21 min read
I Spent a Month Building an AI-Powered Thai Duolingo, Then Realized It Was Not That Simple
Why do I make this tool?
It’s been a while since I’ve written an article. It’s not that I didn’t want to write, but in the past month, almost all my time has been spent on a project.
I must have been learning Thai recently, so I wanted to find an app to help me review. I tried to use Anki and quizlet (and purchased a 1-year membership), but I still found them very difficult to use. First of all, importing the vocabulary is a very troublesome thing. Take pronunciation as an example. If you add phonetic symbols to it, the pronunciation will be inaccurate. It is pure text recognition. If it is displayed in Chinese and English, there will also be problems. Anyway, it is very difficult to use.
And they are not particularly friendly to the Chinese community. They use apps like Hello Talk and Ling, which have messy phonetic symbols and key words and are limited to 10 words per day, so you have to sign up for a membership at every turn.
And these applications themselves do not start from the perspective of students. For example, the AI chat function of some software cannot correlate the words you are learning and your mastery level, and the words are just like abandoning every time we open it every time we learn English, without considering the level of the students at all.
Later I realized that these tools were not designed for "real learning" from the beginning. The more seriously you study, the easier it is to be persuaded to quit.
So I did something really stupid and made one myself.
StudyThai.ai
Why is Thai so difficult?
If you have read Thai, you should know that it does not have commas and periods. One problem is that the effect you see can be similar to iamhappyeveryday. A string may contain multiple words, and no one knows the specific words, because this letter may belong to the previous word or the following word.
There are many non-standard rules, so Thai requires practicing syllable segmentation (but in actual learning, I feel that I am not as good at understanding words as you are, because there are too many irregular words). Basically, you can pronounce the word only after you master it. Although Thai has tone symbols, the tone symbols will have different tones in different words, so it is basically very difficult for people who are learning. Moreover, there are 5 tones in Thai, long and short, unlike Pinyin tone symbols that determine the pronunciation of the current word.

The deepest pit of pronunciation/phonetic symbols
If you just want to learn Thai, you can skip this part; but if you have made language products, you will most likely fall into the same trap.
When we learn a language, we all need phonetic symbols. For example, there are pinyin in Chinese and phonetic symbols in English, which are used to assist pronunciation. Thai is similar, but there is no official standard phonetic symbol. One problem is that you see various auxiliary pronunciations outside, such as "Hello"
Sawadii, sawadee, etc. appeared. For example, "chicken" has gai, kai, khai, etc., which is very confusing.
This also means that we cannot rely on the content output by AI to read the word, so I just use the pronunciation rules in the language school textbook, because it has a relatively standardized set of pronunciation rules. Each consonant and vowel will have a relatively easy-to-understand annotation, but there are still many confusing places, such as the coda. The same letter may be converted into i or y, but it does not say which situation is more special.
Thai does not have 1,234 tones like our pinyin, but is distinguished by common rules and special rules + a tone system. The common rules are to look at the final consonant and initial consonant and then judge the vowel, etc. to determine the tone. The tone system also has some special rules. A tone symbol may have several tones, unlike Chinese, where 1 tone is always 1 tone. There are also various mute rules, continuous reading and hidden sound rules.
Then I used Google notebooklm to import the teaching materials, sorted out the rules, and then asked Claude Code to implement it according to the rules, but because there were too many special cases, for example, a word might be a combination of two separate words. Similar to when we eat, it is actually eat + rice, but because it has 44 consonants, you may make mistakes no matter how you match it (for example: where to eat delicious rice). If you match according to the longest path, you may match the following content (he will think that the above sentence is a word, because it matches eating and rice). It may be the initial consonant of the following syllable, but it is considered by the system to be the tail consonant of your current syllable.
Therefore, the accuracy of the first version of the transliteration engine was only about 50%. Later, I wondered if there was some implementation, and then I actually found a library written by someone else 5 years ago. However, his approach was very bad. He used a thesaurus to cover common words and then implemented transliteration. The problem is that words that are not covered by the vocabulary cannot be transcribed.
So for my second version, I superimposed his thesaurus and the current transcription engine. The accuracy has improved a lot, but there are still many errors.
Then I thought that although Thai is a niche language, it is not unlearned, so I tried to continue searching, and I actually found one. There is an industry that is maintaining it. Their approach uses NLP to analyze the semantics to judge the words before and after and then decide to split it into several syllables. Then our third version pre-installed this service. After analyzing the semantics to determine the split syllables, each syllable was transcribed into IPA according to the transliteration.
The accuracy of the third version has indeed improved a lot, but its analysis fails before a large part of special rule words, and our transliteration is also wrong. Moreover, when faced with long words, such as Bangkok (if you are interested, you can search for the full name of Bangkok), it is difficult to define whether it is a word or a sentence, which also leads to frequent mismatching of syllables. So I was thinking of splitting it into words first, and then splitting it into syllables. Huangtian paid off. I found a thesaurus that summarized abbreviations for similar word rules, similar to a3e4.
Based on the above word rules + NLP semantic analysis + sentence pre-splitting + For syllable splitting, we have freed up the fourth version of the phonetic notation engine. The accuracy of such an engine should be 80%. However, there is also a problem that the NLP service actually has a big performance problem for the transliteration of syllables of words. So I am designing the fifth version and try to use Lexer to rewrite the current transcription engine. Because the current transcription engine matches by characters, in fact, it cannot see the whole word. It can only be patched to search one by one and then transliterate, instead of transcribing the entire word.
The fifth edition is currently under design, but it may not be the best. If there are experts in this field, you can contact me.
How I broke down “Learning Thai” into a few things you can do
Let’s talk about how to make a learning tool. Initially, my idea was to make a tool similar to Anki or quizlet, so that I could easily memorize words. It turned out that many people had similar needs, so I made it into a website and posted it.
Thai is phonetic, so what you see is what you get. Look at Thai pronunciation directly, so you need to learn its consonants and vowels. The same pronunciation may be different combinations of consonants and vowels, so we need to remember what the pronunciation rules of each consonant and vowel are.
So I designed several special trainings specifically for training. Because consonants placed at the first or last part of a word will have different pronunciations, two trainings were specially separated.
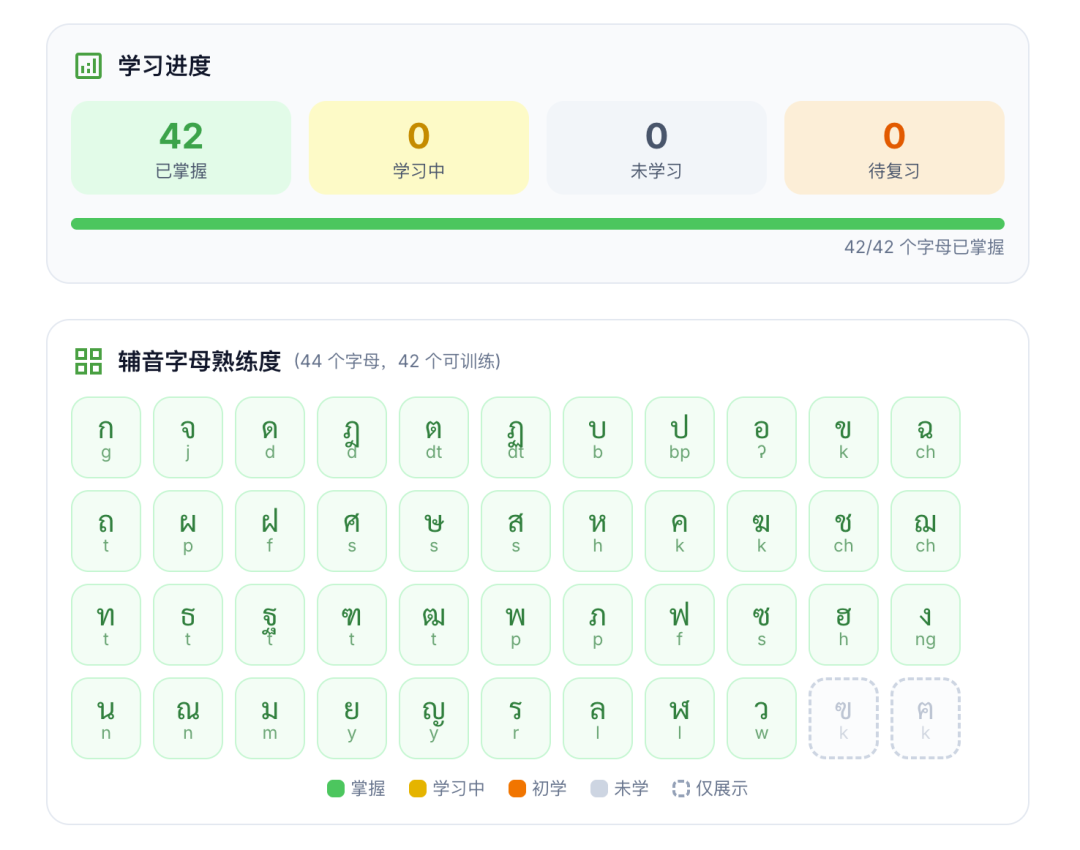
When I found out: Only 6% of people last 7 days
memorize words
After solving the word problem, we still have to return to learning itself. The core of memorizing words still uses the Ebbinghaus spaced repetition algorithm. Simply put, after each learning, the review time is extended again and again. For example, after the first learning, you will be asked to review 10 minutes later, then 1 day, 2-3 days, 7 days, 15 days. Anyway, when you are about to forget, he will appear to help you strengthen your memory.
But there is a big problem with this, that is, once you don't insist on checking in, the more you study, the more you review, and then you look at a bunch of words and you don't want to study anymore. According to my idea, memorizing words is a very boring activity in itself, and it turns out that it is too, because only 6% of people can persist in learning for the second time within 7 days.
For memorizing words, we refer to Duolingo. We have selected Thai by looking at Chinese, choosing Chinese by looking at Thai, syllable assembly, selecting Thai by listening to sounds, and writing Thai by looking at Chinese characters. We have designed a variety of training methods. Although it is not that boring in nature, it still makes me uninterested. After all, I am a bad student. Then I was reflecting on how we usually put useless knowledge into our heads.
For example, when we talk about sheep, sheep, sheep, I wonder how many people think of it. This approach is to force knowledge into your head through a lot of repetition. Then I looked at quizlet and Duolingo, and found that there is a so-called game module, but it was boring and I couldn’t remember it.
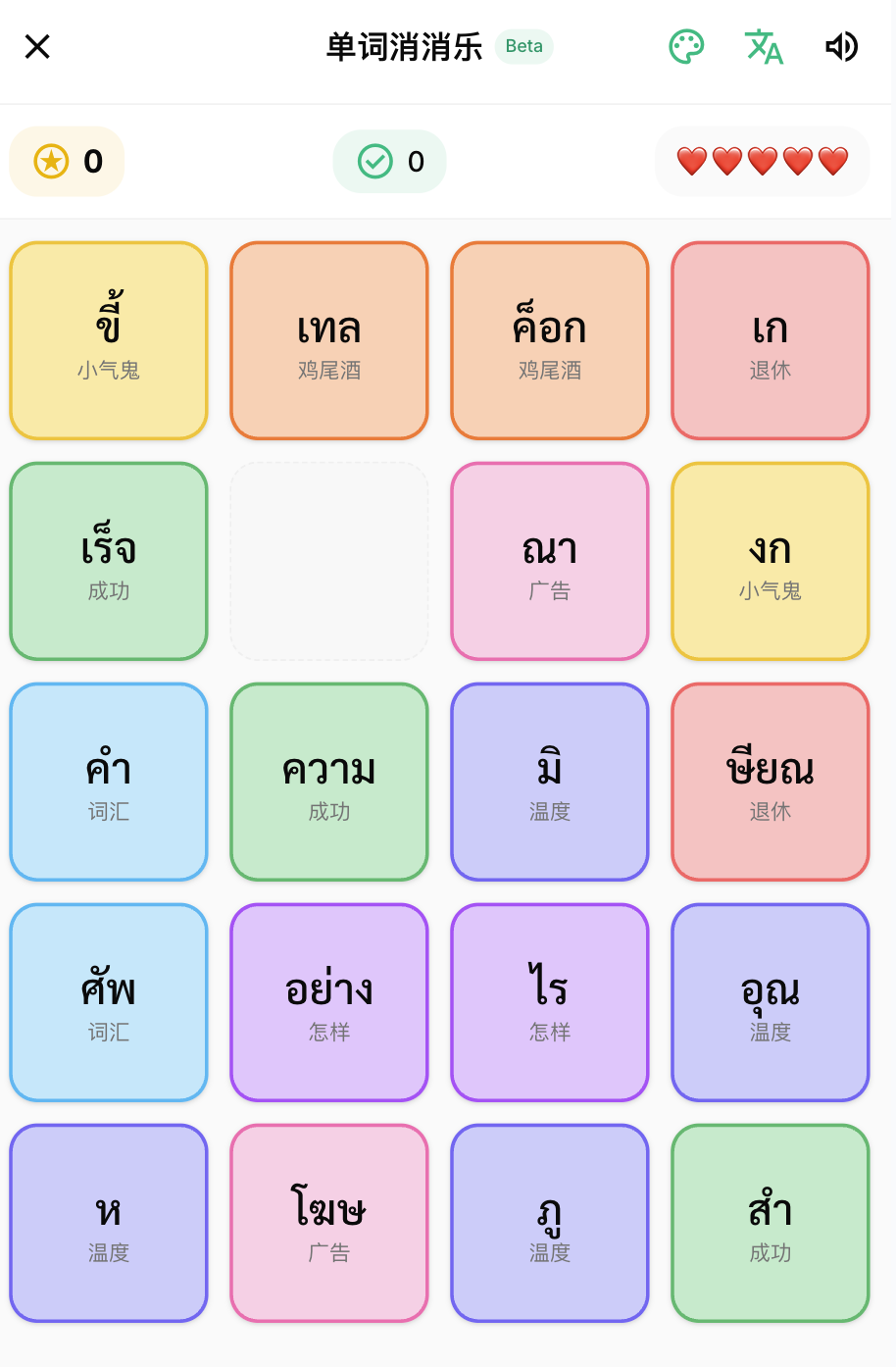
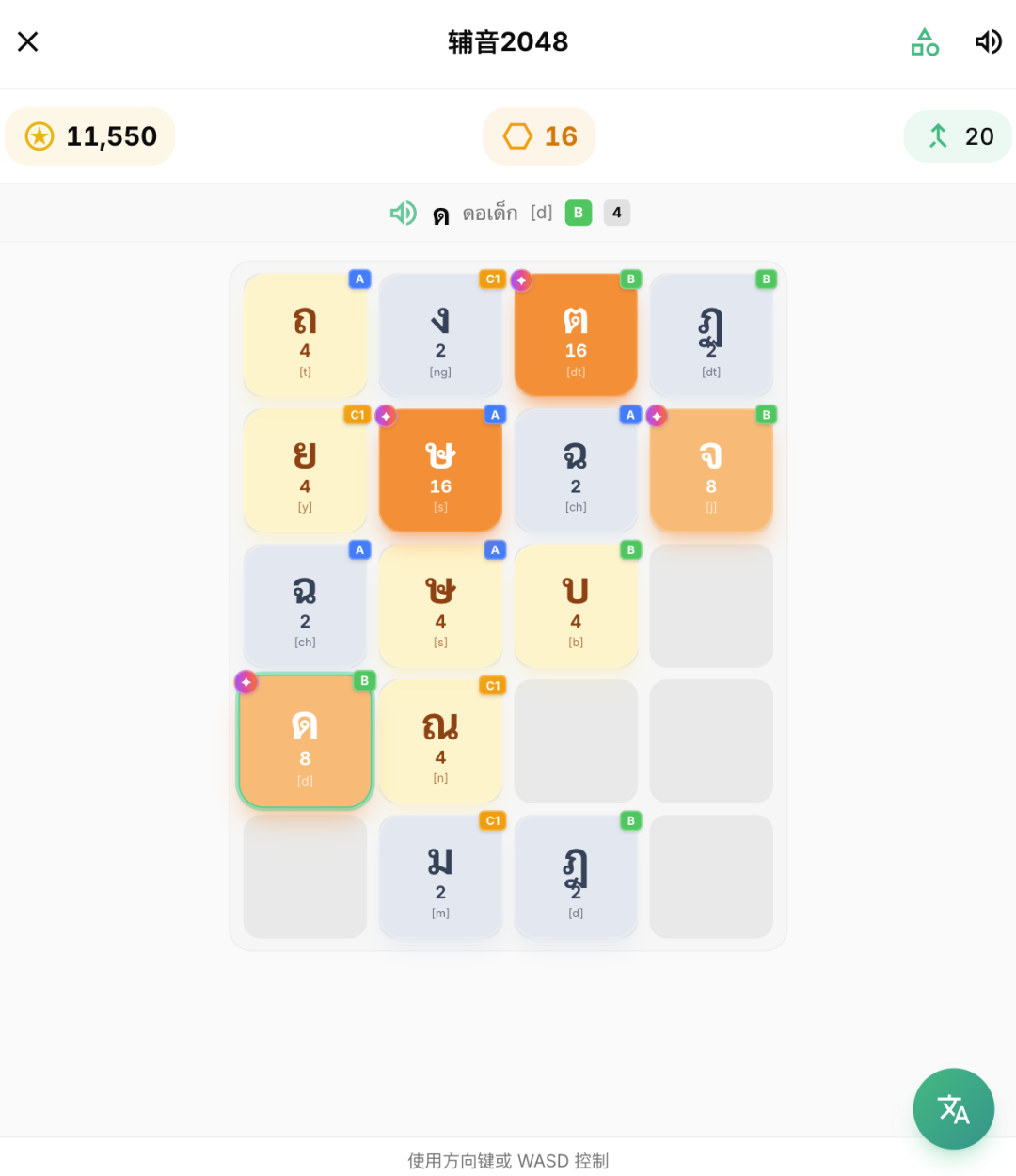
Then I was thinking about what lightweight games everyone usually plays. Through observation, I found that games like Xiaoxiaole and 2048 that don’t require too much brain work are most suitable for passing time. But how to make us want to play more, then scores are definitely needed. Then just design something that keeps you motivated, so I made a ranking list.
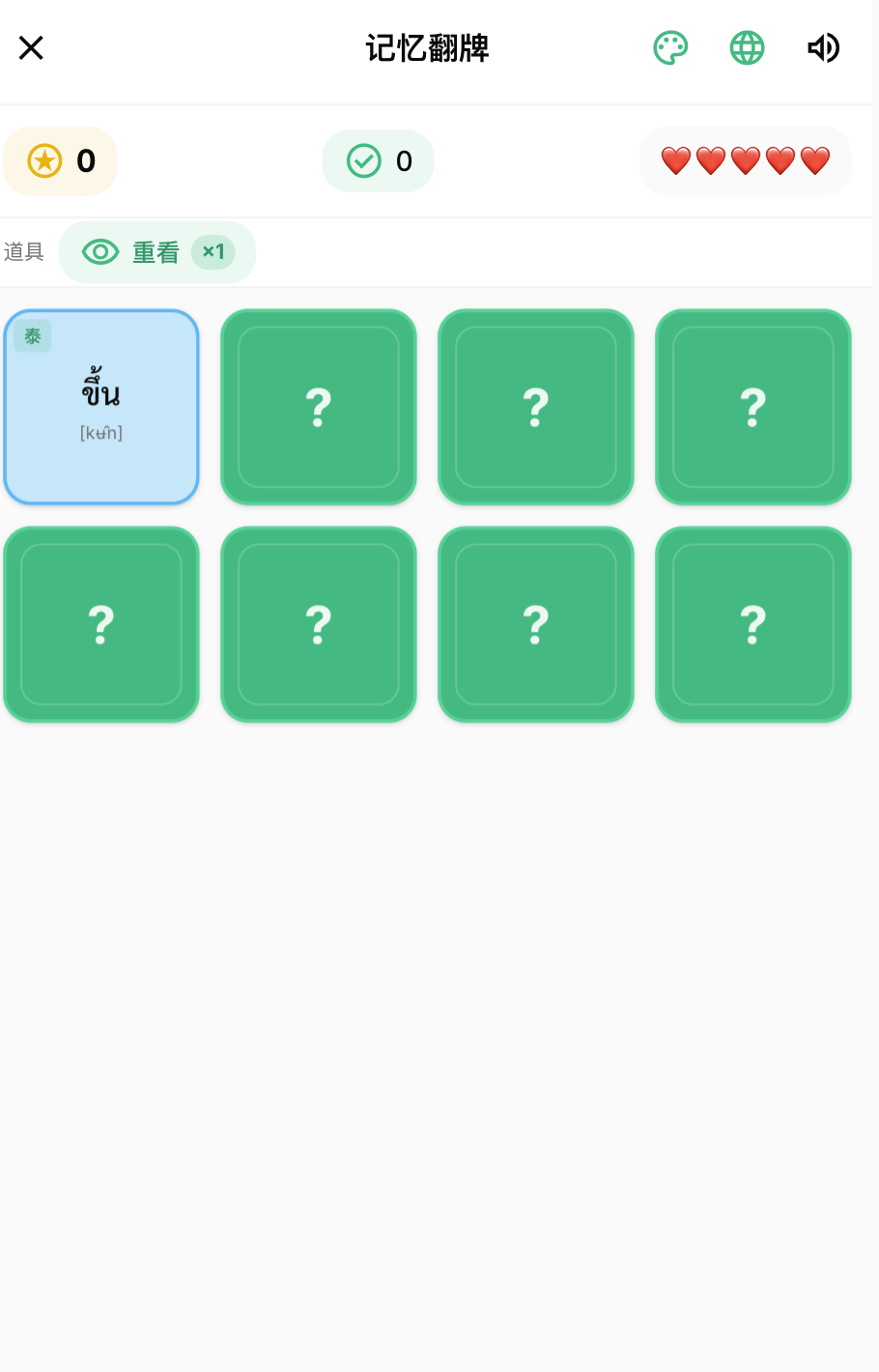
The core of the design is mainly to integrate the current mini-game + word = new gameplay mode. For example, the elimination music becomes the syllable elimination music. You can eliminate the blocks by combining syllables, and finally get a high score. For example, the memory card flip is to memorize Chinese and Thai, turn it over in different positions, and finally get a high score. Consonants 2048 also integrates the gameplay of 2048 into learning consonants. Consonants of the same category can be merged into higher levels to get high scores.
Finally, as long as the pairing is successful, the Thai, Chinese, and broadcast of the word will appear to enhance memory.
Chinese translation
I first wanted to look for any ready-made services or dictionaries, but I couldn't find any. Later, I thought that there might be too little information on Hantai, so I turned to Yingtai, but I couldn't find anything that could be downloaded. Finally, I found a public page that shared 1,000 commonly used Thai words. Later, after it went online, someone reported that the translation was inaccurate, so I tried to deploy a qwen 8b model locally and ran the translation again, but the result was not good.
In the end, I had no choice but to build a large model on the line, but it is not 100% accurate, because the meaning of the word may change as it is used in the sentence, and there are many written words, polite words, etc., but it is basically usable.
Audio / TTS / Mobile rollover
At the beginning, because there were only 1,000 words, I specially pre-recorded 1,000 audios for playback, but many people using mobile browsers said they could not hear the sounds. Later it was discovered that they used custom lexicon databases that were not pre-recorded, so there was no sound.
The reason for the original design of the custom thesaurus was also very stupid, mainly because I am not a professional in education, and my original intention was to have an application that is convenient for me to remember. However, the audio, translation, and IPA display may not be correct, and then I was scolded for misleading people with wrong content. To be honest, except for applications like Anki, which require professional lexicon importing, I have never seen any useful application that can memorize words for free without any restrictions. At that time, I almost got angry and closed the website.
But I have been scolded a lot since I started making independent products this year, so I have some ability to withstand pressure. So I designed a custom thesaurus. The original intention is to let everyone refer to Anki to import a thesaurus by themselves, and it can also facilitate others to subscribe to the thesaurus, which is mutually beneficial. However, I still overestimated the subjective enthusiasm of users. Not many people create thesaurus, and most users actually don't like to mess around with these customized things. It's like if I liked flipping, I might not have this project.
But often if you add something on a whim instead of thinking carefully, it may appear that it is not well thought out. The audio above is an example. Then consider making it a tts playback, but user feedback is sometimes good and sometimes bad. Then I discovered that the TTS of the browser was not stable, and the TTS of the mobile browser was relatively uncontrollable.
Then we turned to commercial TTS, which can maintain a relatively consistent experience in different browsers and different terminals. But a new problem also came, that is, there were various problems when playing on mobile phones. Later, I found out through printing logs that it was a problem with mobile phone permissions. I happened to meet a guy who makes French learning tools. After discussing with him, the solution I came up with was to cache the TTS audio locally, and then play local sound effects to bypass the restrictions of mobile browsers. Then iOS will restrict automatic playback, so the interaction is muted by default. Only after the user clicks Autoplay can they have permission to play the audio automatically.
You see, this is the experience that AI cannot replace. I think vibe coding is so popular now that there should be a market for providing consulting services. Of course, the prerequisite is that you need to receive customers.
When features start costing real money
Because after switching to commercial TTS, the cost is not as fixed as before. Because the previous costs were nothing more than development costs, servers, domain names, and pre-generation costs, this can be estimated. But commercial TTS services are different. As user usage will slowly increase, the cost will also increase first. Although the volume is small now, it cannot be ignored.
So we connected payment, mainly using Stripe, because we have plans to expand to multiple languages later. Alipay subscription needs to be activated by contacting customer service. As for how to activate Stripe, this article will not go into detail.
Payment access is relatively simple. After downloading llms.txt, just let Claude Code access it according to the specifications. Because of the experience of several previous projects, there is basically no problem.
The only embarrassing thing was that I didn't pay for it for 2 weeks after going online, but a customer created customer information. I didn't care about it at first, but later I found out that I forgot to configure the callback link. After all, online testing costs real money, so I made an oversight at that time.
I thought AI reading would be useful, but it’s not
AI reading
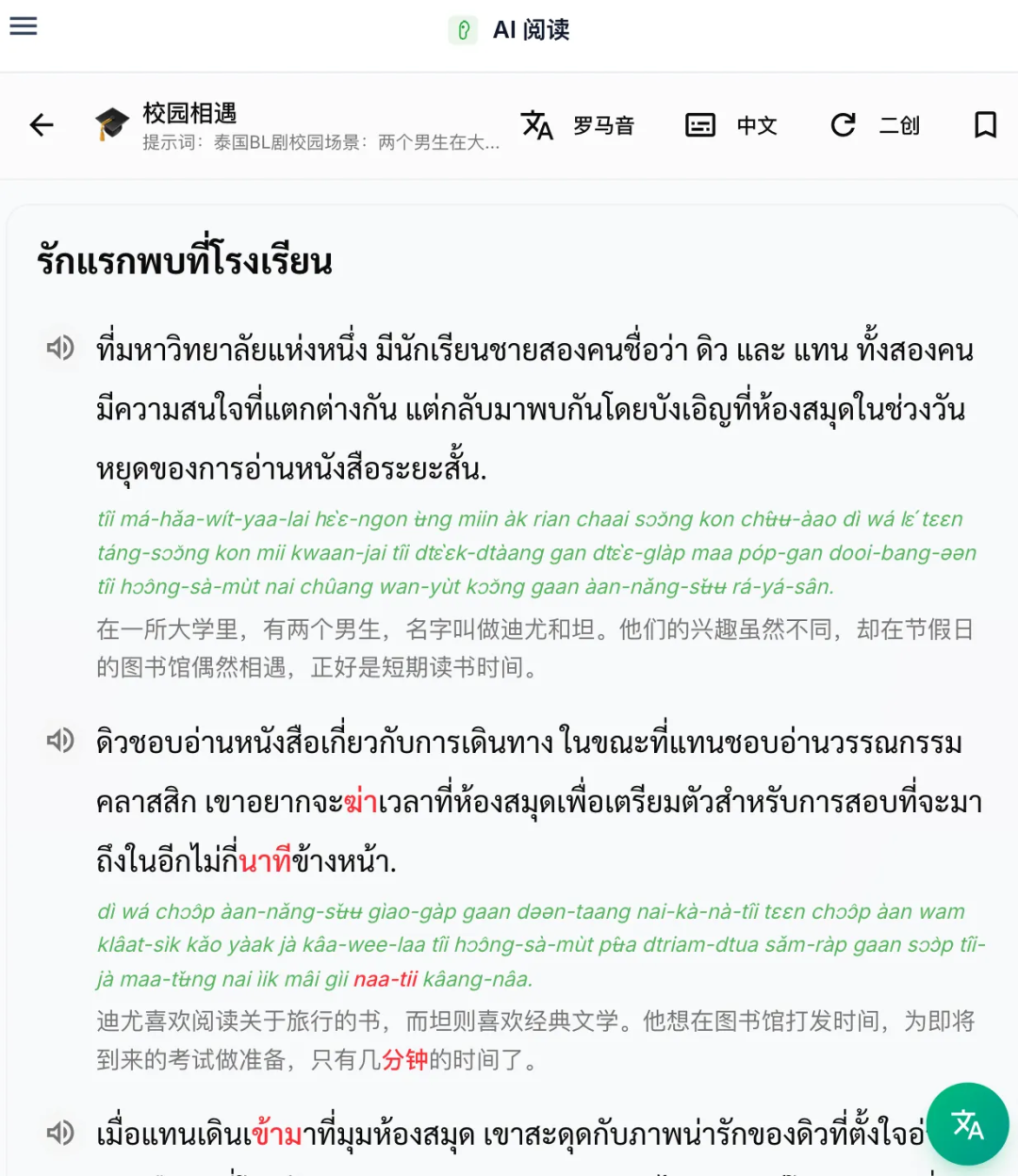
In the process of our learning, as our vocabulary grows, reading comprehension will definitely appear. But the problem with the reading comprehension in the textbook is that I don't care at all how many chickens Zhang San bought or who Li Si met today. So we conceived this function. By getting the words to be reviewed recently, and then generating articles according to the scenarios, I have designed more than 30 scenarios and several major categories, allowing you to generate articles according to your own interests. You can also create new articles based on the generated prompt words of existing articles and write some customized articles.
According to my observations at language schools and users, many users started learning Thai because of Thai celebrities. So I added the Thai pure love scene, which I understood, and sure enough, the scene quickly dominated the charts in the next few days.
However, the answer rate of the article's questions is only 22%, that is, only one of the five articles has anyone answering the question seriously. So I haven't figured out how to improve the conversion rate and optimize this area, because I don't know if everyone is purely curious or really want to learn through the article.
I am an I, and I am embarrassed to harass users. If you have used this function and want to chat with me, please send me a private message.
AI Dictionary
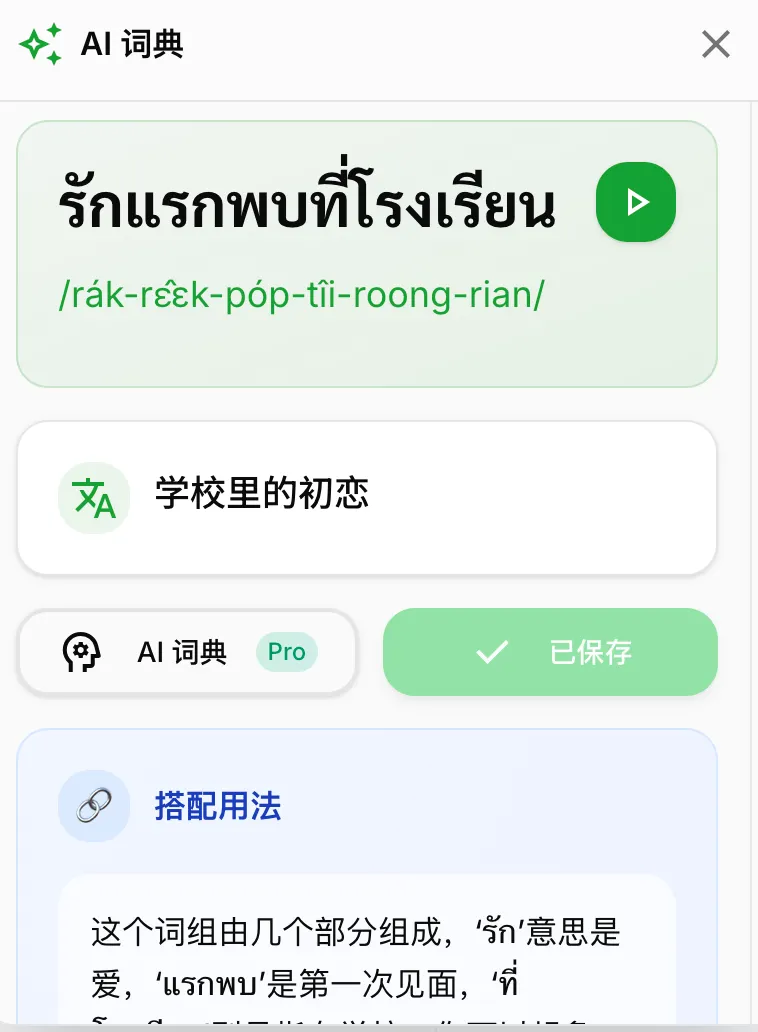
This is mainly because I want to solve the problem between Google Translate and AI learning. In daily life, I often use Google Translate words, but mainly to listen to pronunciation, and sometimes Google Translate is not as accurate as AI. AI mainly depends on the pronunciation of IPA (if it is sometimes inaccurate, but I can solve the Thai letters to correct it), but the most important thing is the explanation of the word, such as multiple meanings, example sentences, etc. to assist understanding. If it is the best, it can be added to our vocabulary library.
So this function was designed, but as a floating ball in a web page carrier, it is not that easy to use. For example, the page is refreshed when you reopen it, etc. However, I found that some users like to use it for translation, but the usage rate for explanation is not that high.
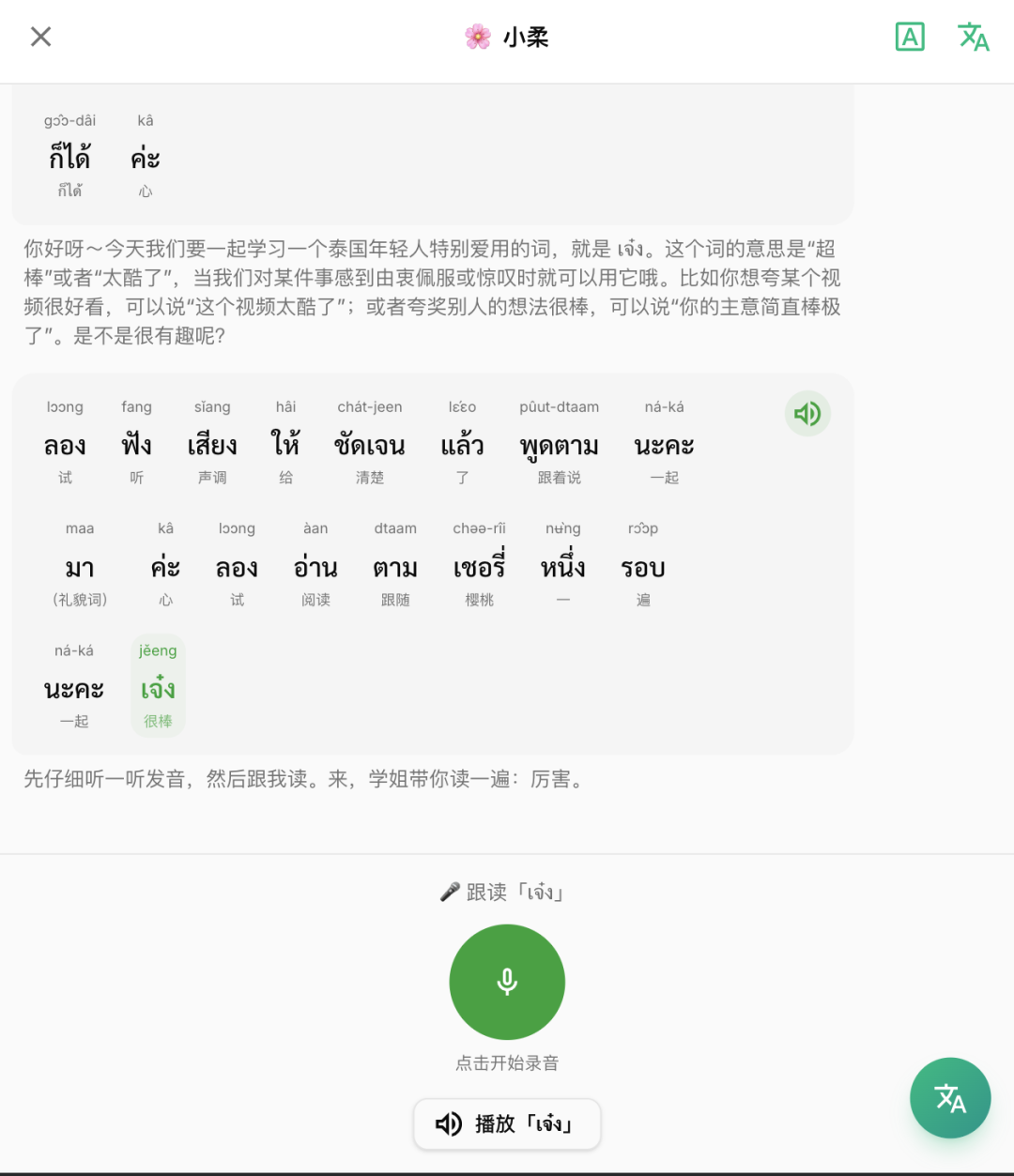
When I try to make AI actually "teach people"
AI teacher
In fact, many of us have stayed at the tool level and solved the problems of listening and reading. But in fact, the problem mentioned has not been solved, because some users have reported to me whether AI pronunciation correction can be done. Gemini Flash 3 has just been launched, and it is said to be very powerful. I searched online to see what it could do, and found that it supports audio input, which means it makes AI audio correction possible.
I encountered several problems in the process. The first one was about process control. I tried to open up the dialogue at the beginning, but it went astray. So what is the difference between asking me directly about GPT? Therefore, I combined the teacher's habit of teaching, first explaining the word in Thai, then reading along, then asking questions, and continuing to expand the questions, allowing students to use the word to answer the questions, and by the way correcting the students' pronunciation, grammar and other issues during the answer process.
I left all the latter process to AI, but it turned out that AI did not follow the process to enter the next stage, so it was changed to be controlled by the system. AI only needs to tell the student whether the result of the following reading or the result of the answer is suitable for entering the next stage.
Then the sentence splitting, transliteration, translation, and audio are all problems that have been solved before, and there are no core technical issues. Later I found a library that can support MP3 recording on the mobile web page, which solved the recording problem.
Then this alone was too boring, so I asked the AI to search for some popular characters in Thai dramas on the Internet (I don’t watch Thai dramas myself), sorted out a few popular characters, and then added them to the character of the AI teacher. However, I don’t watch Thai dramas, so I can’t feel whether they really fit the character.
I won’t say that much about other sporadic small changes and designs. There are 30 documents on function points alone. I’ll let you dig out other surprises or shocks by yourself.
Some real experiences about vibe coding
At present, the core functions are basically complete, but there are still a lot of problems to be solved. Today I will review this project carefully here. This project is also the smoothest project using vibe coding at present. It is a small and medium-sized commercial project written 100% through AI.
We see many projects now, all of which are about 10 minutes of vibe, but few people do a relatively complex project. Of course, we can also see many so-called god-level skills and god-level models, but no one discusses them every time they come out. So I'll share a little bit about how I do it.
Prototype & UI
Although my interface cannot be called exquisite, it does not look like a demo or the AI interface that everyone often sees. Here I will share the way I did this project, that is, we wrote the requirements in Google's stitch and let it produce prototypes. You can take a look at my first version of the interface, and then threw this interface to Claude Code and asked him to make a set of design specifications based on this interface (remember to save the md file). If you are based on some component library (such as shadcn), you can go to the component library website to find his llms.txt, then save it locally, and then follow it with Claude When Code says, introduce this llms, then AI can create this design specification and interface according to shadcn.
Another method is to use Google's aistudio, use the Gemini Pro 3 model (the number of free times is enough for you), and then select Build. At this time, you can go to some websites to find pictures of the design style you like, and then throw them to them. I am just doing a demonstration here. In fact, your needs may be more complex. Then you may get a styled web page. Just pull the resources locally and throw them to Claude Code for processing as above.

document
This is also the most important part. Success or failure is also here. The quality of the document will affect whether your vibe coding can proceed smoothly. My current approach is to create several pieces of content in the docs document directory.
The first block is llms. Here we mainly put some of our commonly used integrations, such as ai sdk, stripe, better-auth, etc. When you want to connect to a service, it is best to see if it has llms.txt. If so, download it and put it locally so that Claude Code can find this content when searching for better integration. But you should also pay attention to the pitfalls inside, such as his files being out of date.
The second part is requirements, which is our demand pool. Because sometimes the demand is very large, we need to discuss the details clearly, including product logic and practical architecture, etc. Each specific document is numbered with a serial number. The requirements documents are similar. You can ask Clade Code to search for better best practices on the Internet to write, and then remember to organize an index document of README.md, so that it can be easily retrieved by AI later. Including later implementation, AI can be used to make plans based on current needs.

The third and most important part is features, which is our function list. There are several parts in it. The main thing is to maintain a separate document for each function, and there are links to other documents in it, so that each function maintains its own small version. Then we also need to maintain a README.md index document and a system update log. For example, I maintain a separate copy of the design system as a function.
tool
Basically, I use several large models. Claude Code is the main development tool. Gemini Pro 3 is mainly used to discuss complex requirements (the 200 yuan subscription I made at the beginning is basically enough for warp and cursor), and codex is used for some requirements.
Cursor currently mainly supports Claude Code when its quota is full, but the same model capability is not as good as Claude Code. I guess because Claude Code uses multiple agents to plan plans, and Cursor is still stuck in planning documents, so the gap in the documents written is still very large.
Antigravity is a very eye-catching IDE. It can mainly buy Gemini Pro 3 with part of the credit. Moreover, its Agent has a built-in browser and can open Chrome to do some operations. This is very good for me who does not know the front end. I no longer need to tell him that something is wrong. In this case, he will run it by himself and run interface screenshots and screen recording analysis. If you ask him to do some design, he will also use nano banana to generate pictures and add them to your web page.
Codex has not come back with GPT-5.2 recently. I think Chatgpt should quickly launch Plan Mode to meet multi-agent planning requirements.
Finally, there is Warp. Warp can solve a lot of data needs and can solve a large part of environmental problems. It is difficult for you to run things in Curosr IDE, but there is no problem in the terminal.
Development experience
Many times, you need human intervention to intervene in the implementation of AI. For example, when Claude Code is planning, you can ask Gemini Pro 3 for some plans and let him give suggestions. Or use ChatGPT to ask, and then send suggestions back to Claude Code, which can greatly improve the effect of your implementation.
But you find that your implementation requires multiple rounds of dialogue. At this time, you should consider entering into planning and discussion, and discuss the detailed plan before letting AI solve it. Then don't rely on the tool's checkpoint, because you are working with multiple tools and multiple models, so you try to use git as the standard. When a function is completed, submit it, and manage your own branches. Needless to say.
at last
If you are learning Thai, or are working on an AI product, educational product, or independent development project, there is a high probability that you will also step into the pitfalls that this article has stepped on.
If you have already used - StudyThai.ai
Feel free to send me a private message to tell me: what’s good about it and what’s bad about it.
Finally, we are offering a 30% off discount at the end of the year, which can be used when subscribing to GJ8CXKZE.