3 min read
"Implementation of Sensitive Word Filtering"
![]()

My friends who understand me know that I have recently been working on a community mini-program, hoping to help everyone create a community mini-program without coding. The content in the community is a very important part, but often there will be people posting inappropriate content (please turn right to P station, thank you), so the most basic prevention and control measures are necessary.
The author is an independent developer, taking on various front-end and back-end outsourcing and part-time work. Whether it's work, technical exchanges, or project discussions, feel free to add me for communication.
Preparation of the Word Bank
First, we can download a word bank from the internet, but the word bank I downloaded is somewhat outdated. If anyone has a newer version of the word bank, please let me know so I can update it.
DFA Algorithm
Generally, one might think of traversal matching, but that is too inefficient. Another option is regular expressions, which intuitively also seem poor.
After checking the information, the DFA algorithm is relatively simple and easy to implement. DFA (Deterministic Finite Automaton) is based on the principle of having a finite set of states and some edges that lead from one state to another, with each edge labeled with a symbol. One state is the initial state, and some states are terminal states. Unlike nondeterministic finite automata, in DFA, there will not be two edges starting from the same state with the same symbol.
Since there are only state changes and no calculations, the efficiency is relatively good. The only downside is that it consumes more memory because it requires storing an entire tree in memory.
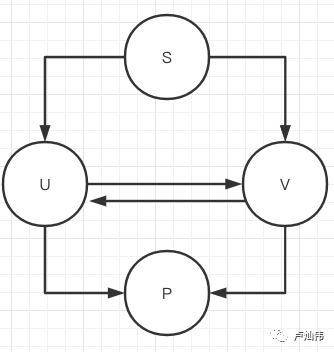
As shown in the figure, we can find P step by step starting from S.
Example
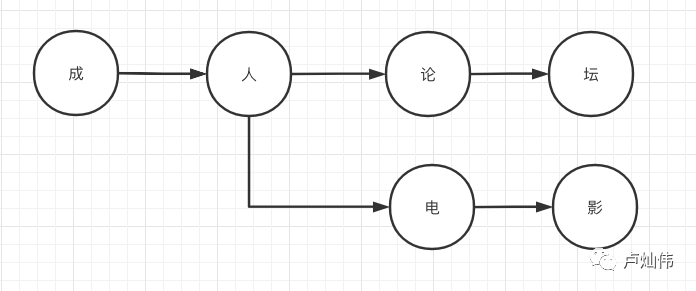
Assuming we have the following two sensitive words in our word bank: adult forum, adult movie, we first need to establish a structure like this.
This can significantly reduce the scope of our search. So how do we determine that the detection of a sensitive word has ended? We need to add a flag to confirm.
Specific Process
1. Data Cleaning
Assuming we have a piece of content like this:
*-`J情成&^人电影在**$#线观看
At this point, our first step is to clean the content, removing special punctuation marks to turn it into plain text.
J情成人电影在线观看
2. Character Exhaustion
First, we exhaust the above text, listing all the possibilities we need to check.
JJ情J情成J情成人J情成人电J情成人电影J情成人电影在J情成人电影在线J情成人电影在线观J情成人电影在线观看
Detection
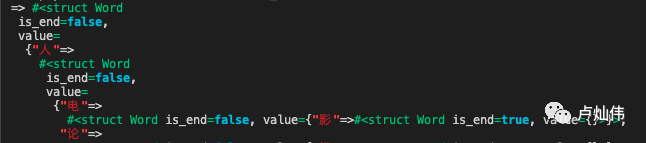
The first two detections do not yield results, but in the third attempt, the character "成" hits the keyword shown above.
We then replace the current detection node from "成" to "人", and so on.
Attached is the implementation of the source code:
```ruby
require "set"
require "pry"
require 'active_support/core_ext'
Word = Struct.new(:is_end, :value)
class FilterSensitiveWord
attr_accessor :words
MIN_MATCH_TYPE = 1
MAX_MATCH_TYPE = 2
def initialize()
@hash = Hash.new
end
def load(file_path)
@words = Set[]
f = File.open(file_path, "r")
f.each_line do |line|
@words.add(line)
end
f.close
to_hash(@words)
end
def to_hash(words)
words.map do |word|
word_hash = @hash
word.strip.chars.to_a.map.with_index do |c,index|
if word_hash[c].blank?
if word.strip.length - 1 == index
word_hash[c] = Word.new(true, Hash.new)
else
word_hash[c] = Word.new(false, Hash.new)
word_hash = word_hash[c].value
end
else
word_hash = word_hash[c].value
end
end
end
@hash
end
def check_sensitive_word(txt, index, match_type)
match_flag = 0
word_hash = @hash
flag = false
txt.each do |w|
if word_hash[w].blank?
break
else
match_flag += 1
if word_hash[w].is_end
flag = true
break if match_type == MIN_MATCH_TYPE
else
word_hash = word_hash[w].value
end
end
end
match_flag = 0 unless flag
match_flag
end