13 分钟
我花了一个月,用 AI 做了一款「泰语版多邻国」,然后发现事情没那么简单
为什么我会做这个工具
有快一段时间没写文章了,不是没想写,而是最近一个月,几乎所有时间都花在一个项目上。
应该最近刚好有在学习泰语,所以想找个应用帮忙复习。我尝试使用Anki和quizlet(并且购买了1年的会员),但是还是觉得非常的不好用,首先词库的导入就是一个蛮烦的事情,就拿发音来说,如果你加入音标在里面,那么就发音不准,他是纯文本识别的。如果中英文显示,也会出问题,反正就是很不好用。
并且对中文圈并没又特别友好,用了像Hello Talk和Ling这种,乱七八糟的音标、关键每天限制 10 个词,动不动就要开一个会员。
并且这些应用本身没从学生的角度出发,比如说有的软件的AI聊天功能就无法关联你正在学习的单词和你的掌握程度,并且单词就是类似我们每次学英语打开每一个开始都是abandon,完全不考虑学生的水平。
后来我意识到,这些工具从一开始就不是为“真正学会”设计的,你学得越认真,越容易被劝退。
于是我干了一件很蠢的事——自己做了一个。
StudyThai.ai
泰语本身为什么这么难
泰文大家如果看过的话应该知道他没有逗号和句号,这样就有一个问题就是你看到的效果能类似iamhappyeveryday,一串里面可能包含多个单词,具体几个单词也没人知道,因为这个字母可能属于前面的单词也可能属于后面的单词。
有很多不标准的规则,所以泰语需要练习音节切分(但是实际学习下来我感觉没你懂单词来的好,因为有太多不规律的单词了),基本上你掌握了你才能念出来这个单词,泰文虽然有声调符号,但是声调符号在不同的单词里会发不同的调,所以基本上对学习的人来说非常的困难。而且泰语里有5个声调,长短音,不像拼音声调符号就是确定当前词的发音。

发音 / 音标这条最深的坑
这一部分如果你只是想学泰语,可以跳过;但如果你做过语言类产品,大概率会踩同样的坑。
我们学习语言的时候都需要有音标,比如汉语里有拼音,英语里有音标,都是辅助发音用的。泰语也类似,但是官方并没有一个标准的音标,导致一个问题就是你看到外面辅助发音各种各样的,比如“你好”
就出现了sawadii、sawadee等等,比如鸡”就有gai、kai、khai等等,非常让人困惑。
这样也导致我们没办法依赖AI输出的内容去读这个单词,所以我就直接拿语言学校的教材里的发音规则,因为他有一套相对规范的发音规则,每个辅音元音都会一个比较好理解的标注,但是还有很多困惑的地方,就像尾音,同一个字母可能会转义成i或者y,但是没说哪种情况是比较特殊的。
泰语里并不像我们拼音那样,是1234声,而是通过常用规则和特殊规则+音调系统来区分,常用规则就是看尾音和声母然后判断元音等来确定声调,然后音调系统也有一些特殊规则,一个音调符号可能有几种声调,不像中文1声永远是1声。还有里面静音规则和连读和隐音规则种种。
然后我使用Google notebooklm把教材导入,然后把规则梳理出来,接着让Claude Code 按照规则实现,但是因为有太多特殊的案例,比如单词可能是一个两个单独的单词合并在一起的。类似我们吃饭,其实是吃+饭,但是因为他辅音就44个,所以你无论如何匹配都可能有错误(举个例子:吃饭去哪去吃好吃的米饭),假设你按最长路径去匹配,可能会把后面的内容匹配进来(他会认为上面的句子是一个单词,因为匹配到吃和饭),他可能是后面音节的声母,但是被系统认为是你当前音节的尾音。
所以第一版的转写引擎的准确率只有50%左右,后来我就想是否有些的实现,然后还真找到了一个5年前别人写的库,但是他的做法非常的不好,就是拿一个词库去覆盖常用词,然后来实现转写。这样的问题就是词库没覆盖到的单词,就无法转写。
所以我第二版我就是叠加了他的词库和现在的转写引擎,准确率提升了不少,但是还是很多错误。
然后我想,虽然泰语是小众语言,但是也不是没有人学,所以我尝试继续寻找,还真被我找到一个。就是有一个业界在维护的,他们的做法通过NLP分析语义来判断前后的词再决定拆分称几个音节。然后我们的第三版本就是在这个前置了这个服务,先通过分析语义来决定拆分的音节后,再把每个音节按照转写转写成IPA。
第三版本的准确率确实提高不少,但是他分析在很大一部分的特殊规则词前就失效了,我们的转写也就错了。而且在面对长词的时候,比如说曼谷(有兴趣可以去搜下曼谷全称),很难界定是一个单词还是一个句子,这也导致音节拆错频频发生。所以我就在想先拆分称单词 ,然后在拆分称音节。皇天不负有心人,我找到了一个词库里有类似单词规则的会汇总简写,类似a3e4这种单词规律。
基于上上面的单词规律 + NLP语义分析 + 句子预拆分 + 音节拆分,我们倒腾出了第四版的音标引擎,这般的引擎准确率应该有80%,但是也有一个问题就是NLP的服务其实对单词的音节的转写其实有很大的性能问题,所以我到在设计第五版,尝试用Lexer的方式重写当前的转写引擎,因为当前转写引擎是按字符匹配的,其实他看不到整个单词全貌,只能类似打补丁去一个个检索后再转写,而不是一整个单词转写。
目前第五版在设计中,但是不一定是最好的,如果有这方面的专家也可以联系我。
我是如何把“学泰语”拆成几件能做的事
这里聊聊如何制作一个学习工具,最初我的构思是做一个类似Anki或者quizlet的这种工具,然后可以方便的背单词,结果发现也有很多人有类似的需求,所以我就做成网站放了出来。
泰文是表音文字,就是所见即所得。看着泰文直接发音,所以需要学习他的辅音元音。同样的发音可能是不同的辅音元音组合,所以我们需要记住每个辅音元音的发音规则是什么。
所以我就设计了几个专项训练,专门用于训练。因为辅音放在单词第一个或者最后一个会有不同的读音,所以专门拆开了两个训练。
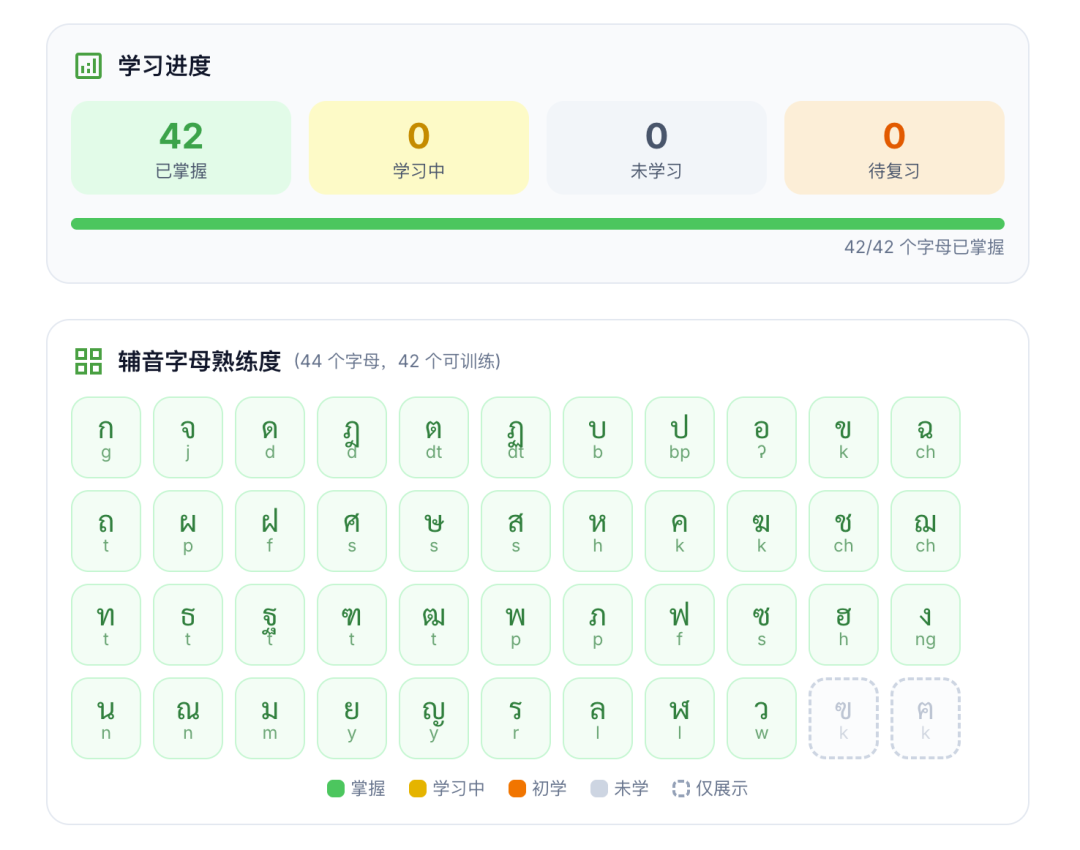
当我发现:只有 6% 的人能坚持 7 天
背单词
解决词的问题后,我们还是要回到学习这件事情本身上,背单词的核心还是采用了艾宾浩斯间隔重复算法,简单说就是每次学完后后面一次次延长复习时间,例如第一次学完后10分钟后会让你复习、然后1天、2-3天、7天、15天,反正你快忘记的时候,他就出现了,帮你加强记忆。
但是这样做有一个很大的问题,就是一旦你不坚持打卡,你学习的越多复习也就越多,然后你看着一堆单词,你就不想学习了。按照我的想法就是背单词本身就是一个很枯燥无聊的行为,事实证明也是,因为只有6%的人能坚持7天内进行第二次学习。
背单词我们参考多邻国,把看中文选择泰文、看泰文选择中文、音节组装、听声音选择泰文、看汉字写泰文等,我们设计了多种的训练方式,虽然本质上没那么枯燥,但是依旧让我提不起兴趣,毕竟是学渣。然后我就在反思平时我们怎么把没用的知识装进脑子。
比如我们现在说羊羊羊,我想知道有多少人联想到什么不。这种做法就是通过大量的重复把知识强加到你脑袋。然后我看了quizlet和多邻国里面相关的,发现有所谓的游戏模块,但很无聊,也记不住。
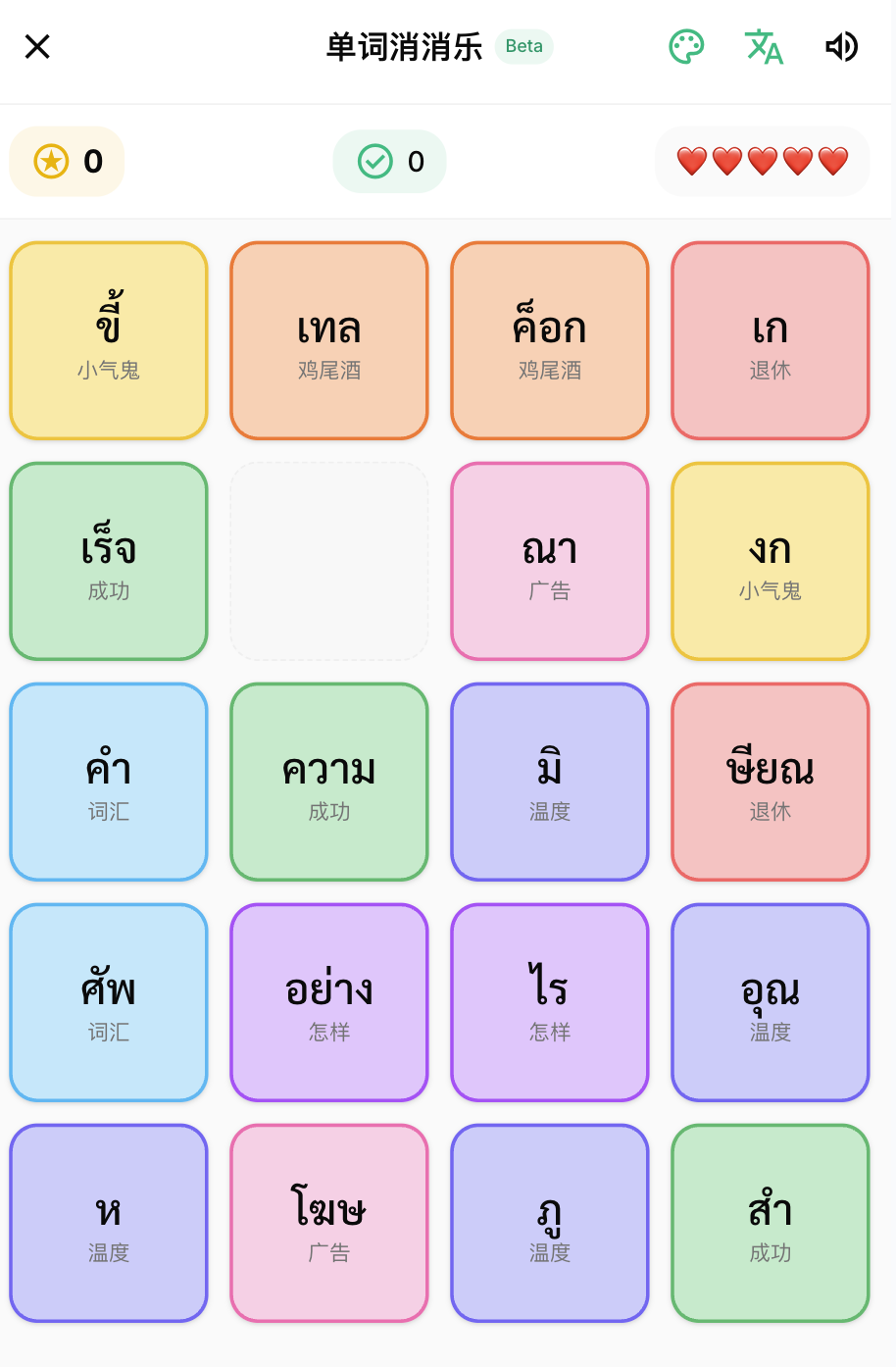
然后我在思考平时大家像有什么轻量的小游戏大家平时会玩的,通过观察,发现消消乐,2048这种不需要太用脑的游戏拿来打发时间最适合,但是如何让我们更加想玩,那么分数肯定是需要的。那么只要设计出一种让你有动力的事情就好了,所以我做了排行榜。
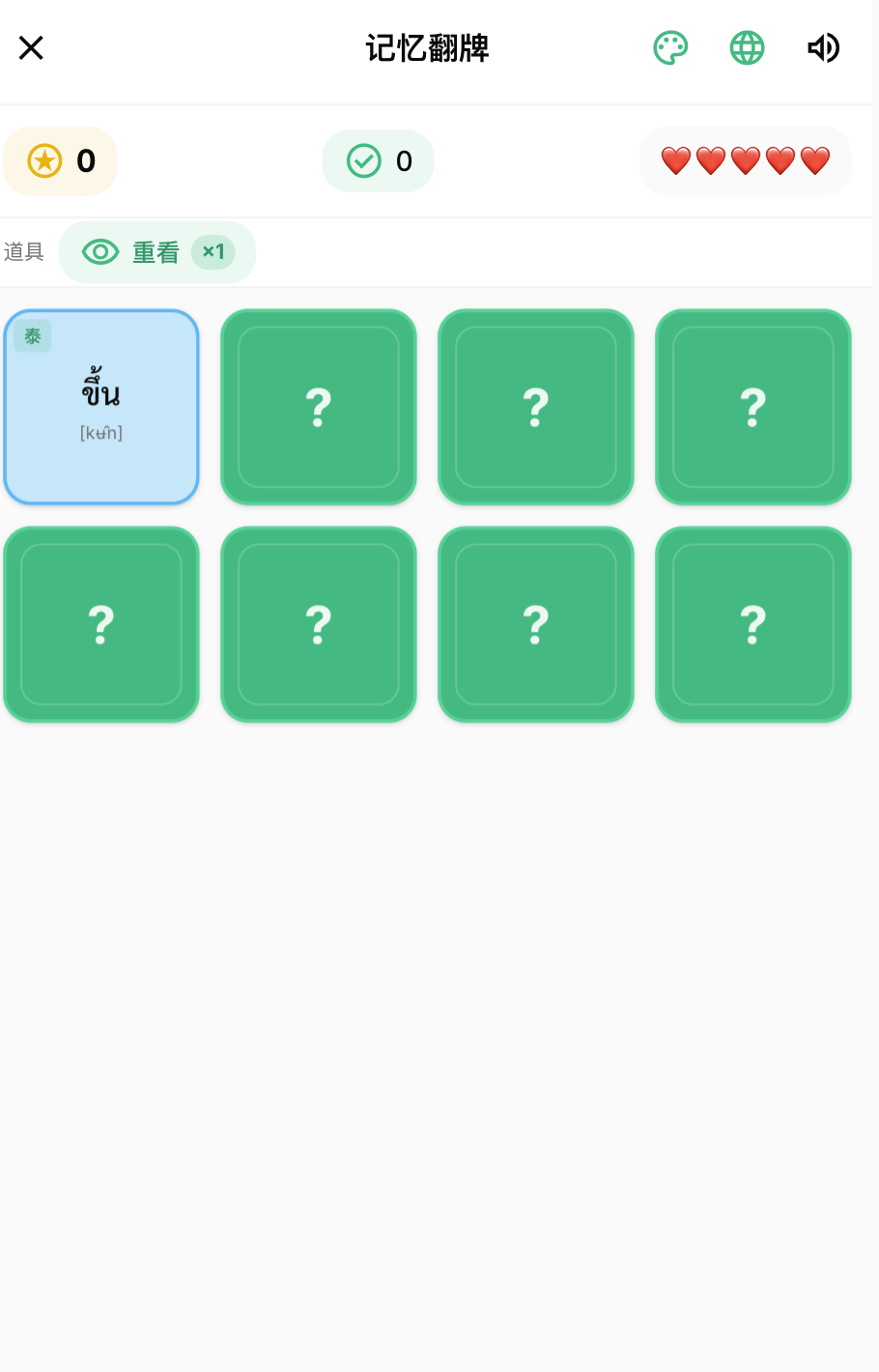
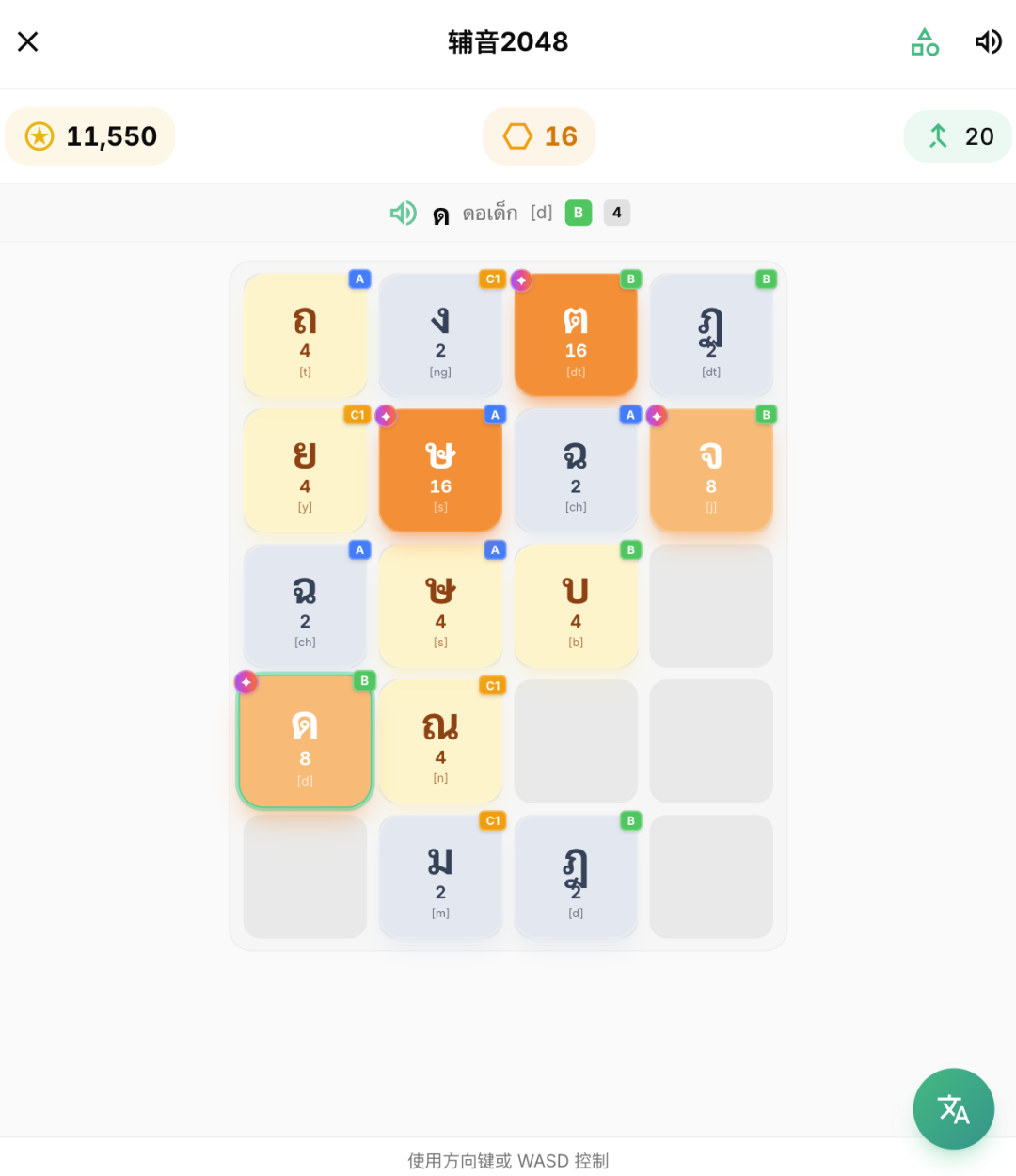
设计的核心主要是把现在的小游戏+单词 = 新玩法的模式整合起来,比如消消乐就变成音节消消乐,通过组合音节来消除方块,最后拿高分。比如记忆翻牌就是通过记住中文和泰文,在不同的位置把他翻开,最后拿高分。辅音2048也是把2048的玩法融入学习辅音,相同分类的辅音能合并更高级别,然后拿高分
最后只要配对成功都会出现单词的泰文、中文、播报去加强记忆。
汉语翻译
我一开始想找有没一些现成的服务或者词典,但是找了一圈都没有。后来想了可能是汉泰的资料太少了,然后就转向找英泰,结果也没找到能下载的。最后我找到一个公开的页面分享的1000个常用泰语单词,后来上线后有人反馈翻译不准,我就尝试用本地部署了一个qwen的8b模型,跑了一遍翻译,出来的效果也不好。
最后无奈氪金跑线上的大模型,但是也不是百分百准确,因为单词的意思可能会随着在句子里发生变化,而且还有很多书写词,礼貌词等,不过也基本上能用。
音频 / TTS / 移动端翻车
一开始因为只有1000个单词,所以我专门预录了1000个音频去播放,但是很多人使用手机浏览器说没办法听到声音。后来发现是他们使用了自定义的词库,这些词库并没有做预录音,所以没声音。
自定义词库当初设计的原因也是非常的狗血,主要是因为我不是专业做教育的,本身的初衷就是想有一个方便自己记忆的应用,但是里面比如说音频、翻译、IPA显示可能都不一定正确,然后就被人骂我用错误内容误人子弟。说真的,除了Anki这种要自己专业去做词库导入的应用,我还真没看到哪个好用的应用可以免费不限制背单词的,当时真的差点生气把这个网站给关闭了。
但是我今年从开始做独立产品后被骂的也不少了,多少有点抗压能力。所以我就设计了自定义词库,本意是让大家参考anki那样自己做一个词库的导入,还能方便别人去订阅词库,互惠互利。不过我还是高估了用户的主观积极性,创建词库的人并不多,大部分用户其实不喜欢去倒腾这些自定义的东西。就好像我要是喜欢倒腾,可能就没有这个项目了。
但是往往你突发奇想而不是深思熟虑加的东西,就可能出现考虑不周全,前面音频就是一个例子。那么就考虑做成tts播放,但是用户反馈时好时坏的。然后我就发现浏览器的tts并不稳定,而且手机浏览器的tts相对不可控。
然后就转向商业的tts,能在不同浏览器,不同终端保持相对一致的体验。但是新的问题也来了,就是手机上播放也是有各种问题,后来发现通过打印日志排查发现是手机权限的问题。刚好推上认识了一个做法语学习工具的大佬,跟他讨论后,得到的方案就是tts的音频缓存到本地去,然后以本地音效播放的方式绕开移动端浏览器的限制,然后ios有会限制自动播放,所以在交互上默认静音,由用户点击自动播放后才能有权限自动播放音频。
你看,这就是AI无法替代的经验,我觉得现在vibe coding这么火,做一个咨询服务应该能有市场,当然前提你要接到客户。
当功能开始花真钱
因为之前转向商业tts后,成本就不像以前那样是固定的了。因为之前的成本无非是开发成本、服务器、域名、预生成的费用,这个是可预估。但是商业tts服务就不一样了,随着用户使用量会慢慢提升,费用也会先行增长,虽然现在体量小,但是也不能不考虑。
所以我们就接入了支付,主要是用Stripe,因为后期有规划拓展到多语言。支付宝的订阅需要联系客服自己去开通。至于如何开通Stripe,这篇文章就不展开说了。
支付接入相对简单,把llms.txt下载后,让Claude Code去按规范接入就行了,因为之前也几个项目的经验,基本上也没啥问题。
唯一发生尴尬的是,上线了2周都没支付,但是有客户创建了客户信息,一开始没在意,后面发现是上线忘记配置了回调链接,毕竟线上测试要花真金白银,所以我当时就疏漏了。
我以为 AI 阅读会很有用,但现实并不是
AI阅读
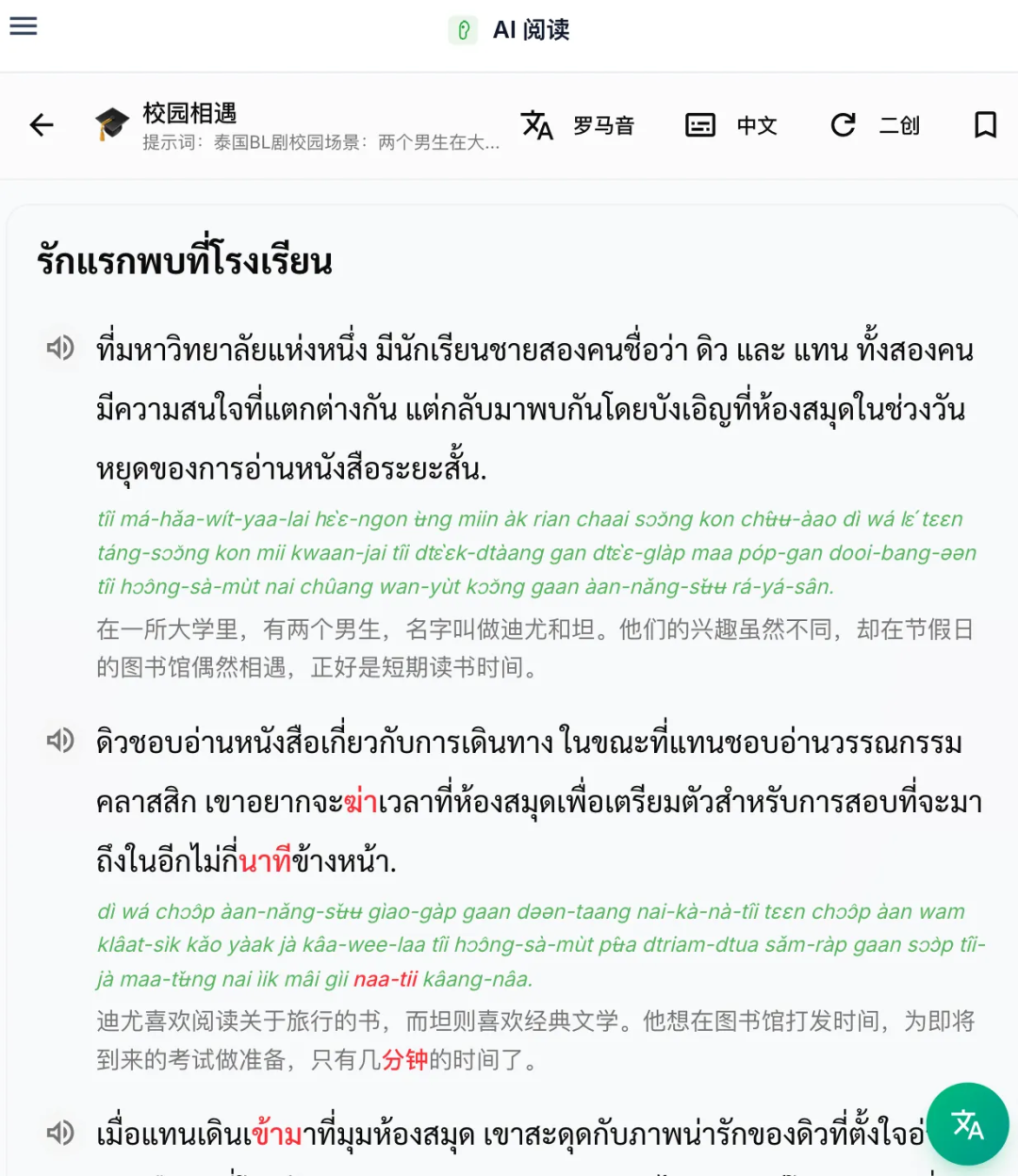
我们学习的过程中,随着词汇量增长,肯定会出现的就是阅读理解。但是教材里的阅读理解的问题在于,我根本不关心张三买了几只鸡,李四今天认识了谁。所以我们构思这个功能,通过获取到最近要复习的单词,然后按照场景生成文章,我大概设计了30多种场景和几大分类,让你根据自己的兴趣生成文章,你还可以根据现有文章的生成提示词进行二创,写一些自定义的文章。
根据我在语言学校的观察和对用户的观察,很多用户都是因为泰国明星才开始学习泰语的。所以我加入泰式纯爱的场景,懂得都懂,果然后面几天该场景迅速霸榜了。
但是文章的题目回答率只有22%,也就是5篇里只有1篇有人认真答题了。所以这块我我还没想好怎么去提高转化率跟优化这块,因为不知道大家是纯粹好奇生成还是真的希望通过文章去学习。
本人是I人,也不好意思骚扰用户,如果你有使用过该功能,想跟我聊聊的欢迎私信我。
AI词典
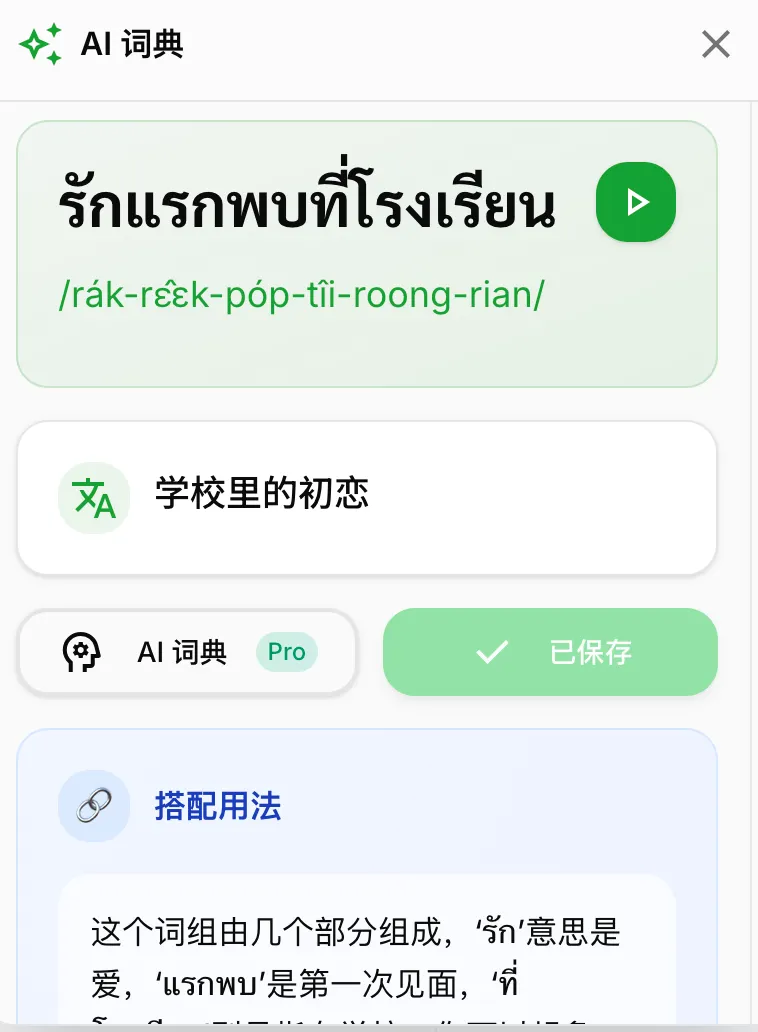
这个主要是我想解决Google翻译和AI学习之间的问题,日常中我经常用Google翻译单词,但是主要拿来听发音,而且有时Google翻译并没有AI准。AI主要是要看IPA的读音(如果有时不准,但是我能解决泰文字母来修正),但是最重要的是这个单词的解释,比如有多个意思、例句等去辅助理解,要是最好的话能加入我们的生词库。
所以设计了这个功能,但是他作为一个网页载体里的悬浮球,并没那么好用。比如重新打开网页页面就被刷新了等等,但是我发现有用户倒是很喜欢使用拿来翻译,但是解释的的使用率并没那么高。
当我试图让 AI 真正“教人”
AI老师
其实前面我们很多都停留在工具层面,解决的是听和读的问题。但是实际上没有解决说的问题,因为有用户跟我反馈是否能做AI纠音。刚好的Gemini Flash 3推出了,据说很强大。我就上网搜了一下大概能做什么,发现他支持audio input,也就是说让AI纠音这个事情变得可能。
中间碰到几个问题,第一个是流程控制的问题,一开始我尝试开放对话,结果就跑偏了,那这样跟我直接问GPT的区别在哪里呢?所以我结合老师上课的习惯,先用泰文解释单词、然后跟读、接着问问题、继续拓展问题,让学生用该单词回答问题,顺便纠正学生回答过程中的发音、语法等问题。
后面这个流程我全交给AI,结果发现AI并不按照流程进入下一阶段,所以改成由系统的来控制,AI只需要告诉这次学生跟读的结果或者回答的结果适合进入下一阶段不。
然后句子的拆分、转写、翻译、音频都是前面解决过的问题,没有什么核心技术问题。后面找到一个库可以支持在手机网页端录制MP3,解决了录音的问题。
然后光是这样就太无聊了,所以我让AI去网上找泰剧里一些比较流行的人设(我本身不太看泰剧),整理出了几个比较流行的人设,然后就加到AI老师的性格里去了,但是我本身不看泰剧,所以感受不到是否真的符合该性格。
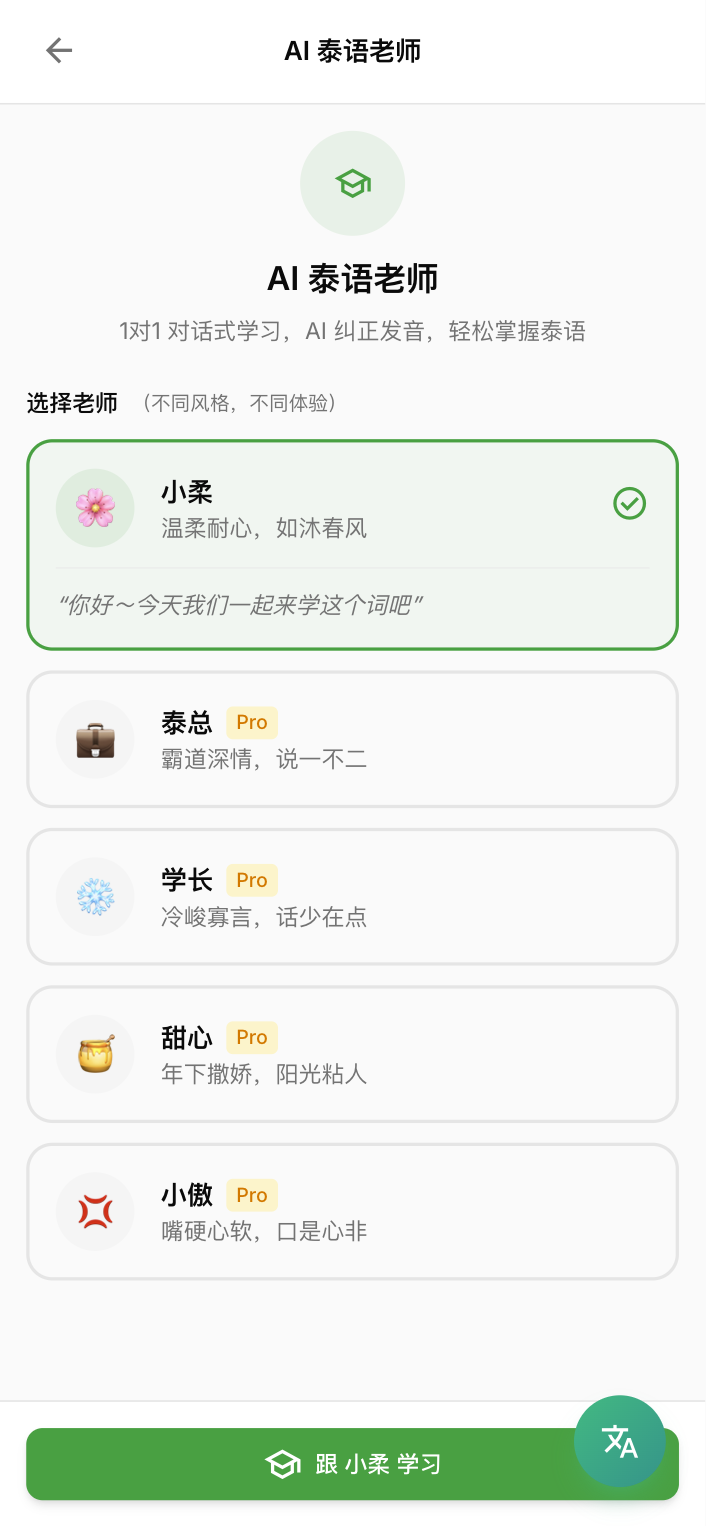
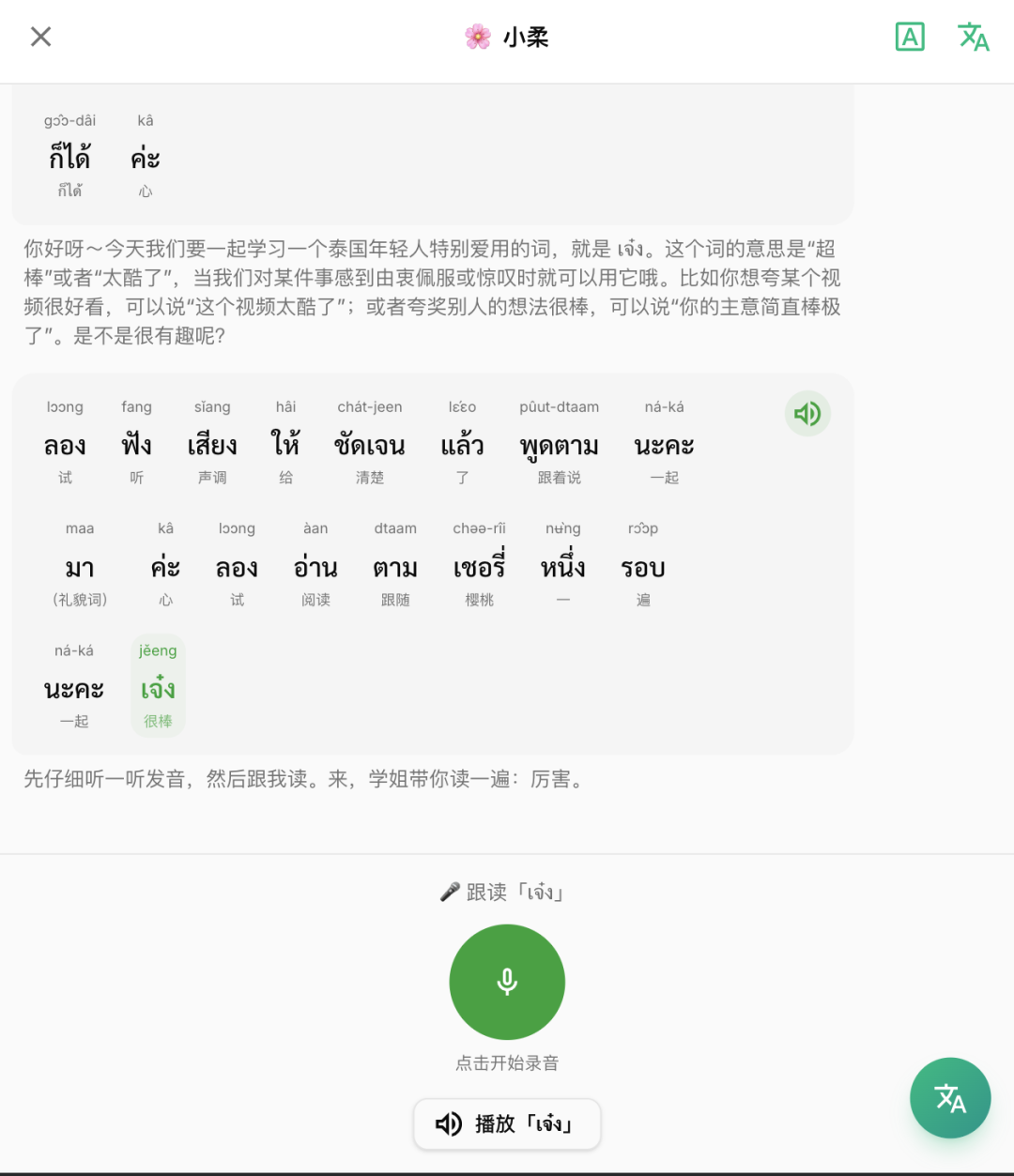
其他零星的小改动和设计我也不说那么多,光是功能点就有30个文档,其他惊喜还是惊吓就让大家自己去挖掘吧。
关于 vibe coding 的一些真实体验
目前核心的功能基本上都完善好了,但是还有一堆问题要解决。今天就在这里好好的复盘一下这个项目,这个项目也是目前使用vibe coding最顺的一个项目,是100%通过AI编写的一个中小型的商业项目。
我们现在看到很多项目,都是说10分钟vibe一个什么出来,但是很少有人做一个相对复杂的项目出来。当然我们也能看到很多所谓的神级技巧和神级模型,但是每段时间出来后就没人讨论了。所以我大概分享一下我这怎么做的。
原型&UI
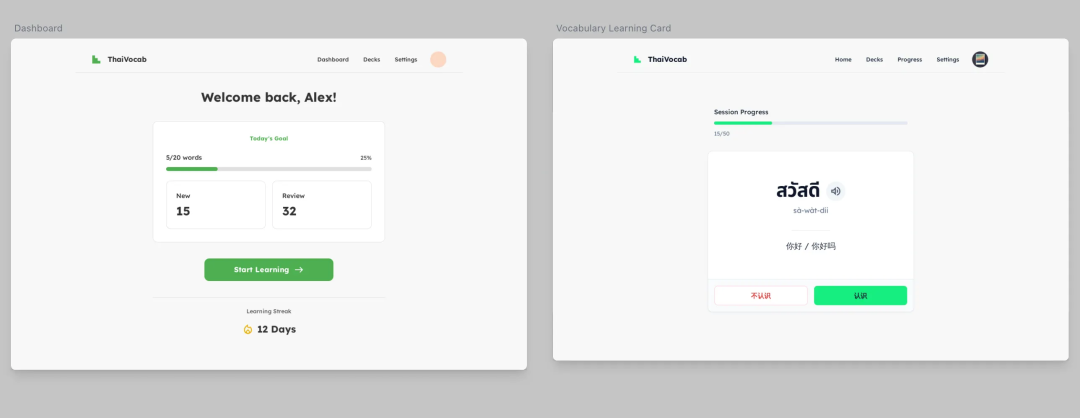
虽然我的界面称不上精致,但是看起来也不像demo,或者大家常看到的ai界面。这里我分享一下我在这个项目里做的方式,就是我们把需求在Google 的 stitch 里编写,让他产出原型图,大家可以看下我第一版本的界面,然后把这个界面丢给Claude Code,让他基于这个界面做一套设计规范(记得保存md文件),如果你是基于某些组件库(比如shadcn),你可以去组件库的网站里找他的llms.txt,然后保存到本地,然后跟Claude Code说的时候引入这个llms,那么AI就能按照shadcn去创建这个设计规范和界面了。
另外一个方法就是通过google的 aistudio,使用Gemini Pro 3模型(免费次数够你使用),然后选择Build,这个时候你可以去一些网站找你喜欢的设计风格的图片,然后丢给他,这里我只是做个演示,实际上你的需求可能更加复杂,然后你可能得到一个风格的网页,跟上面一样把资源拉到本地丢给Claude Code处理就行了。

文档
这个也是最重要的一部分,成败也都在这里,文档的好坏会影响你vibe coding是否能顺利进行下去。我目前的做法是会在docs文档目录下建几块内容,
第一个块是llms,这里主要放入我们常用的一些集成,比如ai sdk、stripe、better-auth等等,当你想接入一个服务的时候,最好看看他有没llms.txt,有就下载下来放到本地,这样Claude Code检索的时候就能找到这篇内容以便更好的集成。但是也要注意里面的坑,比如他的文件过时之类的。
第二块就是requirements,也就是我们的需求池,因为有时候需求很大,我们需要把细节讨论清楚,包括产品逻辑和实践架构等,具体每个文档用序号进行编号,需求文档大同小异,你可以让Clade Code去搜索网上比较好的最佳实践去编写,然后记得需要整理个README.md的索引文档,后续方便AI去检索。包括后面实现的时候可以让AI基于当前需求去做计划。

第三块也是最重要的,就是features,也就是我们的功能列表,里面有几块要主要的就是每个功能单独维护一份文档,并且在里面有其他文档的链接,这样每个功能就自己维护一个自己的小版本。然后也是要维护一份README.md索引文档,并且还有系统的更新日志,比如我把设计系统单独维护了一份,作为功能。
工具
基本上我几个大模型都在使用,主力开发是Claude Code,复杂需求讨论主要用Gemini Pro 3(当初撸的200块订阅目前warp、cursor基本够用),然后部分需求用codex。
cursor目前主要是在Claude Code 满额度的时候顶一下,但是同样的模型能力实在不如Claude Code,我猜测因为Claude Code用多Agent去规划Plan,而Cursor目前还停留在规划文档上,所以写出来的文档差距还是很大的。
Antigravity 是非常亮眼的IDE,主要可以白嫖部分额度的Gemini Pro 3,而且他的Agent内置了浏览器,可以打开Chrome去做一些操作,这个对于不懂前端的我来说就非常不错了,不再需要跟他说那里不对,这样的话,他会自己跑然后去运行界面截图和录屏分析,如果你让加做一些设计他还会用nano banana生成图片然后添加到你网页里。
Codex最近GPT-5.2并没有扳回一城,我觉得Chatgpt还是赶紧上线Plan Mode去进行多Agent规划需求吧。
最后就是Warp,对于很多数据的需求可以用Warp解决,能解决很大一部分环境的问题,你在Curosr IDE里运行东西很困难,但是终端里就没问题了。
开发经验
很多时候,你需要人为的介入干预AI的实施,比如说Claude Code在规划的时候,有些方案你可以拿去Gemini Pro 3去问问,然后让他给建议。或者用ChatGPT问问,后续把建议给回Claude Code,这样很大程度能提高你实施的效果。
但你发现你实施需要进行多轮对话,这个时候就要考虑进入规划和讨论,把详细的方案讨论清楚后再让AI再去解决。然后不要依赖工具的checkpoint,因为你是多个工具,多个模型工作,所以你尽量以git为准,当一个功能做好了就提交,管理好自己的分支啥的都不用说了。
最后
如果你正在学泰语,或者正在做一个 AI 产品、教育产品、独立开发项目,这篇文章踩过的坑,大概率你也会踩。
如果你已经用过 - StudyThai.ai
欢迎私信我告诉我:它到底哪里好用,哪里烂。
最后送上一个年底7折优惠,GJ8CXKZE 订阅的时候可以使用。