5 分钟
独立开发周记24: 我做了一个AI漫剧的应用
这周强度有点大,现在都可以在家待2-3天不出门了,主要是最近新的内容太多了,刚好今天主要没更新啥内容。
Confirmo
大家应该有印象我之前开源过一个R2的uploader,当时图标是一只贱兮兮的猫头鹰,所以我做了一个雪碧图,提交到Confirmo后,他就可以监控你的AI Coding的状态,这玩意是推特上的大神搞的,不过实际用下来提醒不是很准,估计目前没办法很好抓到完成情况

openclaw
这玩意经历了三次改名,从clawdbot 到 moltbot 到 openclaw,非常魔幻,买域名炒关键字估计都要亏一波。为了抛除成见,我决定自己在Mac mini上装一下,看看可用性。
他有一个web界面,我通过Cloudflare Zero Trust 和 Cloudflare Tunnel 建立了一个公网访问的地址。Cloudflare Tunnel 主要可以让你本地的一个端口绑定一个域名,然后我通过Cloudflare Zero Trust 建立一个白名单,就是需要通过我的白名单里的邮件验证码进行验证后才能打开网页,tg我设置了一个白名单,只绑定我的账户,所以基本上安全性这块没啥问题。
这几天我研究一下别人咋玩的,很多人都是在炒作流量,或者赶潮流,反正装好后问个天气,或者每天发个新闻之类的,可能我是不太看那些无关新闻的人,所以我觉得都是在赶潮流。
回到生产力这块,随着AI时代的来临,你会发现你生产力提高了,一个人可以顶一个团队,但是你的专注力不够。比说我现在同时跑2个不同的项目,脑力的切换成本就高,再多我就负担不了了。
既然定位是个人助理的话,我希望这玩意可以帮我管理和做决策判断,我用了很多产品,也自己开发了类似的产品,但是都不太满意。所以我做了一个Skills,用来做数据的链接和收集,让OpenClaw去对接好我配置的服务,然后再通过对话完成我要的内容。
运营日报
得益lennysbundle送的一个Posthog会员,我把埋点数据都上报,还有错误日志和一些info的打点数据。然后我再我的work-skills让OpenClaw配置好后(关键的APIKEY我得自己去电脑上设置),让OpenClaw自己去拉Posthog的数据,然后做成日报每天发给我。
跟原来最大的区别是,我不需要额外通过AI Coding去改脚本自己去管理cron的这一堆事,报表有啥疑问也可以随时询问和他聊天更新。
自动修复bug
我配置好了Github后,让他自己去拉昨天Posthog的错误,然后分析错误原因和修复代码,最后review,然后运行测试后创建PR,然后消息给我。
先观察一下这几天的质量,如果好的话可以扩大修复的范围。
其他目前还没时间研究,目前看到是让AI自己去做交易之类的,我有个项目也是类似,不过这玩意要花时间。
StudyThai
说下项目吧,Level3课程上线后,准备开始做APP了。之前调研了半天Tauri,一堆问题多到我想哭。我想说如果只是webview包装而已,为啥我要搞这么复杂。所以直接用flutter来写,感动哭了,没到半小时就封装好,可以开始改了。
主要思路分几块,一个是标题栏+tab的原生化,然后就是tts和录音等一些功能的原生化,最后是整个APP的UI统一更新
UI的设计通过Google Stitch来做,让Claude Code整理一下我们现在所有页面,然后读取代码去生成Google Stitch的提示词,然后调用MCP去生成,然后我在Google Stitch去微调,最后全部下载到本地后,读取html文件进行UI的重构。
尽管很多细节可能没那么好,但是已经比当前版本的UI更加具备设计感了。不过重构的过程中还是有很多问题,比如桌面端的设计和网页端和ap端就有明显不一样,因为ap用的原生的标题栏,桌面和网页也不一样。
还有就是网页和原生通讯的问题,app页面堆栈的问题,这些都要进行测试,说起来挺麻烦的。
AI-drama
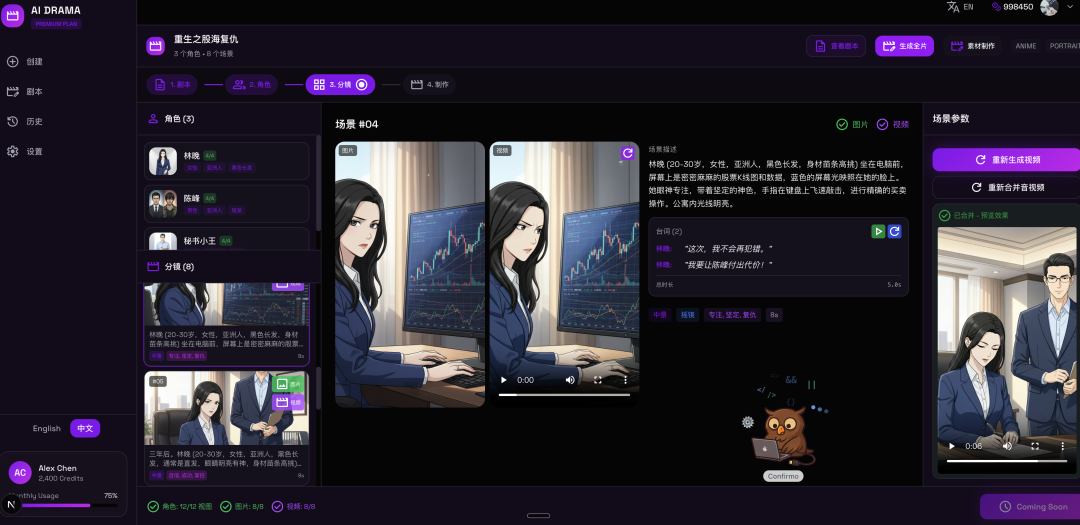
这个项目也是一个满好玩的事情,就是推特上有个蛮网红的团队,我也有兴趣,然后就投了。然后聊了一下,出了个题目要考察,大概就是你有没能力做,然后你的代码能啥,让我做一个AI漫剧。
毕竟我也是老油条了,也不会傻逼兮兮的白干,所以我说核心代码我不会给你,前端代码你可以review到整体关于项目代码管理相关的能力,对方说好,然后给了一个测试的图片Api key。
因为本身我自己对这块感兴趣,一个是最近经常刷到好奇如何实现,另外一个是我们StudyThai的AI阅读我完成率有点低,所以我一直想着把这块拓展一下,把你学习的单词变成一部剧本视频、文章、漫画之类的,所以借着这次的事情我就花了点时间研究了一下。
这玩意果然比我想象的复杂,从提示词 - 剧本 - 分镜 - 视频,这些其实都不难,无非就是对接和调试的问题。但是难的地方在业务逻辑,实现方案一直在改,主要时间都花在这里。
下面是我碰到的一些问题,如果你也在做这块可以参考一下,或者你有更加好的方案也能告诉我
人物需要生成不同角度的图片,然后图片有一致性的问题(解决方案:通过传入图片和调整提示词让生成的角度图片保持一致性)
分镜不连贯的问题:(VGoT 5D)的一个标准,就是给分镜额外添加一些信息,比如角色的动态、背景环境、开始结束描述、人物关系、镜头信息、灯光信息等,这样可以让你创建视频的时候有更加的连贯问题
视频不连贯的问题:通过一些支持首尾帧的视频生成,比如我现在的使用的veo3.1,这样把当前分镜的图片和下一个分镜的图片传入,就能衔接到下一个分镜
然后就是最困难的一个是视频和台词的问题,因为你无法预测视频生成的内容。
因为veo3.1有很严格审查机制,比如说你给台词,可能就出发了音频过滤导致视频无法生成。所以我想到了让角色嘴巴动起来,但是很遗憾一样触发了嘴巴的限制。查了一些方案都是后期再通过修改唇达到说话的效果,没有细细研究,看起来是一个比较麻烦的方案。
目前改成自然语言描述表情,但是不涉及嘴巴,所以导致人物说话很不明显,只是表情。而且有时还会出现字幕和英语台词(veo自己加的)
然后我就想着看看有没想一些专业的提示词,没想到找到一个还可以的来自 PureACT 官方教程,他大概分成7块,用JSON来控制,然后提交给veo。整体故事描述有帮助,但是解决对话的问题。
但是我们视频和音频还是无法对应上,主要是在因为视频从0.5s-2.5s主角在说话,但是视频可能不一定按照我们的来,这个时候音频又是其他的时间,两边对不上。
然后我尝试用elevenlabs按单词的时间戳,然后再传给视频生成。后面尝试很久发现elevenlabs对中文的支持太差了。然后我找到了微软的edge tts做语音的生成,有专门中文的声音,用下来效果还不错。
最后通过ffmpeg清除视频的声音,然后合并音频进去,但是又发现时间对不上,结果是因为视频是自己说了英文和中文对不上,所以调整prompt,暗示语言。但是目前没一个好的办法让他一定遵守我们的台词时间轴,这里就需要抽卡了,抽一次不便宜。
目前AI漫剧还没达到可以产品的使用,我很好奇其他人咋做的,自己把视频抽卡和音频抽卡后自己通过剪影做后期吗?
最后
扯了那么多,聊点小技巧。
如果大家使用都谷歌账户都可以使用gemini cli,你可以在claude code里建立一个翻译skill,通过gemini调用完成,我现在翻译很多走这个,不浪费claude code的token
另外一个是建立一个codex的code review skill, 因为codex的代码审查普遍强过claude code,所以我也让claude code接入进来了